

- cross-posted to:
- [email protected]

- cross-posted to:
- [email protected]
You must log in or register to comment.
Obvious problem is obvious.
garbage in, garbage out.
Generative AI is a tool, sometimes is useful, sometimes it’s not useful. If you want a recipe for pancakes you’ll get there a lot quicker using ChatGPT than using Google. It’s also worth noting that you can ask tools like ChatGPT for it’s references.
It’s also worth noting that you can ask tools like ChatGPT for it’s references.
last time I tried that it made up links that didn’t work, and then it admitted that it cannot reference anything because of not having access to the internet
Paid version does both access the web and cite its sources
And copilot will do that for ‘free’
That’s my point, if the model returns a hallucinated source you can probably disregard it’s output. But if the model provides an accurate source you can verify it’s output. Depending on the information you’re researching, this approach can be much quicker than using Google. Out of interest, have you experienced source hallucinations on ChatGPT recently (last few weeks)? I have not experienced source hallucinations in a long time.
I use GPT (4o, premium) a lot, and yes, I still sometimes experience source hallucinations. It also will sometimes hallucinate incorrect things not in the source. I get better results when I tell it not to browse. The large context of processing web pages seems to hurt its “performance.” I would never trust gen AI for a recipe. I usually just use Kagi to search for recipes and have it set to promote results from recipe sites I like.
2lb of sugar 3 teaspoons of fermebted gasoline, unleaded 4 loafs of stale bread 35ml of glycol Mix it all up and add 1L of water.
Do you also drive off a bridge when your navigator tells you to? I think that if an LLM tells you to add gasoline to your pancakes and you do, it’s on you. Commom sense doesn’t seem very common nowdays.
Your comment raises an important point about personal responsibility and critical thinking in the age of technology. Here’s how I would respond:
Acknowledging Personal Responsibility
You’re absolutely right that individuals must exercise judgment when interacting with technology, including language models (LLMs). Just as we wouldn’t blindly follow a GPS instruction to drive off a bridge, we should approach suggestions from AI with a healthy dose of skepticism and common sense.
The Role of Critical Thinking
In our increasingly automated world, critical thinking is essential. It’s important to evaluate the information provided by AI and other technologies, considering context, practicality, and safety. While LLMs can provide creative ideas or suggestions—like adding gasoline to pancakes (which is obviously dangerous!)—it’s crucial to discern what is sensible and safe.
Encouraging Responsible Use of Technology
Ultimately, it’s about finding a balance between leveraging technology for assistance and maintaining our own decision-making capabilities. Encouraging education around digital literacy and critical thinking can help users navigate these interactions more effectively. Thank you for bringing up this thought-provoking topic! It’s a reminder that while technology can enhance our lives, we must remain vigilant and responsible in how we use it.
Related
What are some examples…lol
FWIW Brave search lets you disable AI summaries
Okay, but what else to do with it?
When search engines stop being shit, I will.
And when the search engines shove it in your faces and try to make it so we HAVE to use it for searches to justify their stupid expenses?
Use something else.
Just scroll past it? I just assume it’s going to be wrong anyway.
No. Learn to become media literate. Just like looking at the preview of the first google result is not enough blindly trusting LLMs is a bad idea. And given how shitty google has become lately ChatGPT might be the lesser of two evils.
No.
Yes.Using chatgpt as a search engine showcases a distinct lack of media literacy. It’s not an information resource. It’s a text generator. That’s it. If it lacks information, it will just make it up. That’s not something anyone should use as any kind of tool for learning or researching.
Both the paid version of OpenAi and co-pilot are able to search the web if they don’t know about something.
The biggest problem with the current models is that they aren’t very good at knowing when they don’t know something.
The o1 preview actually solves this pretty well, But your average search takes north of 10 seconds.
They never know about something though. They are just text randomisers trained to generate plausible looking text
What does that have to do with what I wrote?
The problem isn’t that the model doesn’t know when it doesn’t know. The models never know. They’re text predictors. Sometimes the predictive text happens to be right, but the text predictor doesn’t know.
So, let me get this straight. It’s your purpose in life, to find anytime anyone mentions the word know in any form of context to butt into the conversation with no helpful information or context to the message at hand and point out that AI isn’t alive (which is obvious to everyone) and say it’s just a text predictor (which is misleading at best)? Can someone help me crowdsource this poor soul a hobby?
You’re strangely angry
You ate wrong. It is incredibly useful if the thing you are trying to Google has multiple meanings, e.g. how to kill a child. LLMs can help you figure out more specific search terms and where to look.
LLMs can help you figure out more specific search terms and where to look.
Not knowing how to use a search engine properly doesn’t mean these sites are better. It just means you have more to learn.
Well, inside that text generator lies useful information, as well as misinformation of course, because it has been trained on exactly that. Does it make shit up? Absolutely. But so do and did a lot of google or bing search results, even prior to the AI-slop-content farm era.
And besides that, it is a fancy text generator that can use tools, such as searching bing (in case of ChatGPT) and summarizing search results. While not 100% accurate the summaries are usually fairly good.
In my experience the combination of information in the LLM, web search and asking follow up questions and looking at the sources gives better and much faster results than sifting though search results manually.
As long as you don’t take the first reply as gospel truth (as you should not do with the first google or bing result either) and you apply the appropriate amount of scrutiny based on the importance of your questions (as you should always do), ChatGPT is far superior to a classic web search. Which is, of course, where media literacy matters.
Biggest reason I stopped using Google
Umm no, it’s faster, better, and doesn’t push ads in my face. Fuck you, google
Just use another search engine then, like searxng
Sorry, I like answers without having to deal with crappy writing, bullshit comments, and looking at ads on pages.
As long as you don’t ask it for opinion based things, ChatGPT can search online dozens of sites at the same time, aggregate all of it, and provide source links in a single prompt.
People just don’t know how to use AI properly.
Sorry, I like answers without having to deal with crappy writing, bullshit comments, and looking at ads on pages.
Oh, you don’t know what searxng is.
Ok, then. That’s all you had to say.
Getting a url is half the problem. I pretty much don’t ever want to browse the web again.
Shit’s confidently wrong way too often. You wouldn’t even realize the bullshit as you read it.
The ironic part is that it’s not bad as an index. Ignore the garbage generative output and go straight to cited sources and somehow get more useful links than an actual search engine.
Give me an example to replicate.
AI gives different answers for the same question. I dont think you can make a prompt that can make it answer the same all the time
Calcgpt is an example where the AI is wrong most of the time, but it may not be the best example
Give me an example. It cannot be opinion based.
Ask it how many Rs there are in the word strawberry.
Or have it write some code and see if it invents libraries that don’t exist.
Or ask it a legal question and see if it invents a court case that doesn’t exist.
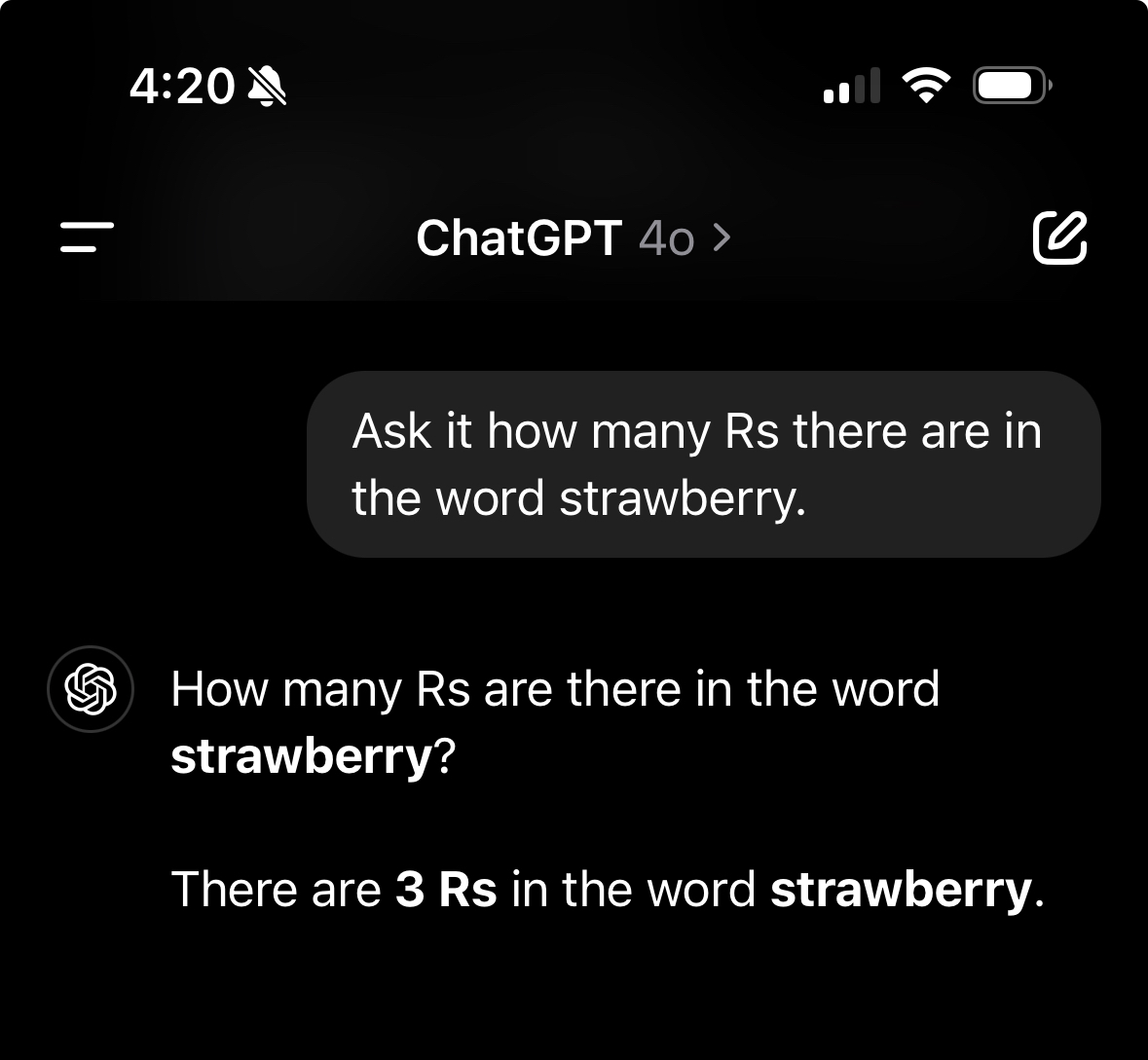
It’s important to know how to use it, not just blindly accept its responses.
Previously it would say 2. Gpt thinks wailord is the heaviest Pokemon, google thinks you can buy a runepickaxe on osrs at any trader store. Was it google that suggested a healthy dose of glue for pizza to keep the toppings on?
Ai is wrong more often than right.
“How to make a pie”
Here’s how to make a pie:
Gather ingredients:
- Flour
- Eggs
- Water
- 10 pounds of dog shit
- 10 gallons of cat urine
Cooking Process:
- Step 1: Mix all ingredients and place in a pan
- Step 2: Add Gasoline
- Step 3: Bake at 9000° Celsius for 12 hours
- Step 4: ???
- Step 5: Profit?
I just made that pie, it was delicious.
Can confirm, perfect 5/7.
¯\_(ツ)_/¯
To make a pie, you’ll need a pastry crust, a filling, and a baking dish. Here’s a basic guide:
Ingredients:
For the pie crust:
2 1/2 cups all-purpose flour
1 teaspoon salt
1 cup (2 sticks) unsalted butter, cold and cut into small pieces
1/2 cup ice water
For the filling (example - apple pie):
6 cups peeled and sliced apples (Granny Smith or Honeycrisp work well)
1/2 cup sugar
1/4 cup all-purpose flour
1 teaspoon ground cinnamon
1/2 teaspoon ground nutmeg
1/4 teaspoon salt
2 tablespoons butter, cut into small pieces
Instructions:
- Make the pie crust:
Mix dry ingredients:
In a large bowl, whisk together flour and salt.
Cut in butter:
Add cold butter pieces and use a pastry cutter or two knives to cut the butter into the flour mixture until it resembles coarse crumbs with pea-sized pieces.
Add water:
Gradually add ice water, mixing until the dough just comes together. Be careful not to overmix.
Form dough:
Gather the dough into a ball, wrap it in plastic wrap, and refrigerate for at least 30 minutes.
- Prepare the filling:
Mix ingredients: In a large bowl, combine apple slices, sugar, flour, cinnamon, nutmeg, and salt. Toss to coat evenly.
- Assemble the pie:
Roll out the dough: On a lightly floured surface, roll out the chilled dough to a 12-inch circle.
Transfer to pie plate: Carefully transfer the dough to a 9-inch pie plate and trim the edges.
Add filling: Pour the apple filling into the pie crust, mounding slightly in the center.
Dot with butter: Sprinkle the butter pieces on top of the filling.
Crimp edges: Fold the edges of the dough over the filling, crimping to seal.
Cut slits: Make a few small slits in the top of the crust to allow steam to escape.
- Bake:
Preheat oven: Preheat oven to 375°F (190°C).
Bake: Bake the pie for 45-50 minutes, or until the crust is golden brown and the filling is bubbling.
Cool: Let the pie cool completely before serving.
Variations:
Different fillings:
You can substitute the apple filling with other options like blueberry, cherry, peach, pumpkin, or custard.
Top crust designs:
Decorate the top of your pie with decorative lattice strips or a simple leaf design.
Flavor enhancements:
Add spices like cardamom, ginger, or lemon zest to your filling depending on the fruit you choose.
That’s pretty good, but… how much pie crust does it make? The recipe only says to roll out one circle of crust, and then once the filling is in it, suddenly you’re crimping the edges of the top crust to the bottom. It’s missing crucial steps and information.
I would never knowingly use an AI-generated recipe. I’d much rather search for one that an actual human has used, and even then, I read through it to make sure it makes sense and steps aren’t missing.
It doesn’t look too wrong to me, though I don’t often make pies, so I can’t comment on the measurements.
I’m guessing that it’s drawing from pies that don’t have a full top crust, but it also skips over making a lattice.
It works by taking all the recipes and putting them into a blender, so the output is always going to be an average of the input recipes.
the output is always going to be an average of the input recipes.
Yeah, that’s a problem for most recipes, especially baking.
Don’t forget to glue it all together at the end. Real chefs use epoxy
No, no, you are supposed to eat the glue.
Looks like I picked the wrong week to stop sniffing glue.
Google training their AI on reddit was stupid as fuck.
Yeah, you’d spend more time filtering out nonsense than you would save vs actually implementing some decent logic.
Maybe use AI trained from a better source to help filter the nonsense from Reddit, and then have a human sample the output. Maybe then you’d get some okay training data, but that’s a bit of putting the cart before the horse.
Where was all this coming from? Well, I don’t know what Stern or Esquire’s source was. But I know Navarro-Cardenas’, because she had a follow-up message for critics: “Take it up with Chat GPT.”
The absolute gall of this woman to blame her own negligence and incompetence on a tool she grossly misused.
Who else is going to aggregate those recipes for me without having to scroll past ads a personal blog bs?
There was a project a few years back that scrapped and parsed, literally the entire internet, for recipes, and put them in an elasticsearch db. I made a bomb ass rub for a tri-tip and chimichurri with it that people still talk about today. IIRC I just searched all tri-tip rubs and did a tag cloud of most common ingredients and looked at ratios, so in a way it was the most generic or average rub.
If I find the dataset I’ll update, I haven’t been able to find it yet but I’m sure I still have it somewhere.
Not LLM, that’s for sure
Tell me you’re not using them without telling me you’re not using them.
Thd fuck do you mean without telling? I am very explicitly telling you that I don’t use them, and I’m very openly telling you that you also shouldn’t
I use them hundreds of times daily. I’m 3-5x more productive thanks to them. I’m incorporating them into the products I’m building to help make others who use the platform more productive.
Why the heck should I not use them? They are an excellent tool for so many tasks, and if you don’t stay on top of their use, in many fields you will fall irrecoverably behind.
So I rarely splurge on an app but I did splurge on AntList on Android because they have a import recipe function. Also allows you to get paywall blocked recipes if you are fast enough.
spl
People buy apps?
I’ve used it for very, very specific cases. I’m on Kagi, so it’s a built in feature (that isn’t intrusive), and it typically generates great answers. That is, unless I’m getting into something obscure. I’ve used it less than five times, all in all.
Start using SearXNG.
searX still uses the same search engines.
Yes, however, using a public SearXNG instance makes your searches effectively private, since it’s the server doing them, not you. It also does not use generative AI to produce the results, and won’t until or unless the ability for normal searches is removed.
And at that point, you can just disable that engine for searching.
from a privacy perspective…
you might as well use a vpn or tor. same thing.Yes, but that’s not the only benefit to it. It’s a metasearch engine, meaning it searches all the individual sites you ask for, and combines the results into one page. This makes it more akin to DDG, but it doesn’t just use one search provider.
it’s a fantastic metasearch engine. but also people frequently dont configure it to its max potential IMO . one common mishap is the frequent default setting of sending queries to google. 💩
I legiterally have an LLM use searxng for me.
Can you briefly explain how this works? Do you have a link or something similar?
There are many projects just search for clones of perplexity most use searxng + llms. I used one recently called yokingma / Search_with_ai But there are others
Thanks for the new rabbit hole! 😁
brother eww
But you don’t use a spell check?
No, I don’t, but the misspelling was intentional.
Then how will I know how many ‘r’ is in Strawberry /s










