
Hello, I’m a bit new to advanced linux and programming stuffs… Can someone explain me why compiling exists and what this process does and how to do it in the principals situations (I’ve heard that you can use the “makepkg” command). Thx to everyone who replied.
Others here have already given you some good overviews, so instead I’ll expand a bit more on the compilation part of your question.
As you know, computers are digital devices - that means they work on a binary system, using 1s and 0s. But what does this actually mean?
Logically, a 0 represents “off” and 1 means “on”. At the electronics level, 0s may be represented by a low voltage signal (typically between 0-0.5V) and 1s are represented by a high voltage signal (typically between 2.7-5V). Note that the actual voltage levels, or what is used to representation a bit, may vary depending on the system. For instance, traditional hard drives use magnetic regions on the surface of a platter to represent these 1s and 0s - if the region is magnetized with the north pole facing up, it represents a 1. If the south pole is facing up, it represents a 0. SSDs, which employ flash memory, uses cells which can trap electrons, where a charged state represents a 0 and discharged state represents a 1.
Why is all this relevant you ask?
Because at the heart of a computer, or any “digital” device - and what sets apart a digital device from any random electrical equipment - is transistors. They are tiny semiconductor components, that can amplify a signal, or act as a switch.

A voltage or current applied to one pair of the transistor’s terminals controls the current through another pair of terminals. This resultant output represents a binary bit: it’s a “1” if current passes through, or a “0” if current doesn’t pass through. By connecting a few transistors together, you can form logic gates that can perform simple math like addition and multiplication. Connect a bunch of those and you can perform more/complex math. Connect thousands or more of those and you get a CPU. The first Intel CPU, the Intel 4004, consisted of 2,300 transistors. A modern CPU that you may find in your PC consists of hundreds of billions of transistors. Special CPUs used for machine learning etc may even contain trillions of transistors!
Now to pass on information and commands to these digital systems, we need to convert our human numbers and language to binary (1s and 0s), because deep down that’s the language they understand. For instance, in the word “Hi”, “H”, in binary, using the ASCII system, is converted to 01001000 and the letter “i” would be 01101001. For programmers, working on binary would be quite tedious to work with, so we came up with a shortform - the hexadecimal system - to represent these binary bytes. So in hex, “Hi” would be represented as
48 69, and “Hi World” would be48 69 20 57 6F 72 6C 64. This makes it a lot easier to work with, when we are debugging programs using a hex editor.Now suppose we have a program that prints “Hi World” to the screen, in the compiled machine language format, it may look like this (in a hex editor):
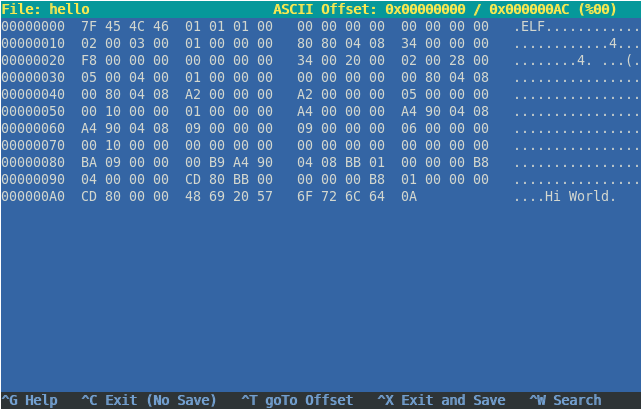
As you can see, the middle column contains a bunch of hex numbers, which is basically a mix of instructions (“hey CPU, print this message”) and data (“Hi World”).
Now although the hex code is easier for us humans to work with compared to binary, it’s still quite tedious - which is why we have programming languages, which allows us to write programs which we humans can easily understand.
If we were to use Assembly language as an example - a language which is close to machine language - it would look like this:
SECTION .data msg: db "Hi World",10 len: equ $-msg SECTION .text global main main: mov edx,len mov ecx,msg mov ebx,1 mov eax,4 int 0x80 mov ebx,0 mov eax,1 int 0x80As you can see, the above code is still pretty hard to understand and tedious to work with. Which is why we’ve invented high-level programming languages, such as C, C++ etc.
So if we rewrite this code in the C language, it would look like this:
#include <stdio.h> int main() { printf ("Hi World\n"); return 0; }As you can see, that’s much more easier to understand than assembly, and takes less work to type! But now we have a problem - that is, our CPU cannot understand this code. So we’ll need to convert it into machine language - and this is what we call compiling.
Using the previous assembly language example, we can compile our assembly code (in the file
hello.asm), using the following (simplified) commands:$ nasm -f elf hello.asm $ gcc -o hello hello.oCompilation is actually is a multi-step process, and may involve multiple tools, depending on the language/compilers we use. In our example, we’re using the
nasmassembler, which first parses and converts assembly instructions (inhello.asm) into machine code, handling symbolic names and generating an object file (hello.o) with binary code, memory addresses and other instructions. The linker (gcc) then merges the object files (if there are multiple files), resolves symbol references, and arranges the data and instructions, according to the Linux ELF format. This results in a single binary executable (hello) that contains all necessary binary code and metadata for execution on Linux.If you understand assembly language, you can see how our instructions get converted, using a hex viewer:

So when you run this executable using
./hello, the instructions and data, in the form of machine code, will be passed on to the CPU by the operating system, which will then execute it and eventually printHi Worldto the screen.Now naturally, users don’t want to do this tedious compilation process themselves, also, some programmers/companies may not want to reveal their code - so most users never look at the code, and just use the binary programs directly.
In the Linux/opensource world, we have the concept of FOSS (free software), which encourages sharing of source code, so that programmers all around the world can benefit from each other, build upon, and improve the code - which is how Linux grew to where it is today, thanks to the sharing and collaboration of code by thousands of developers across the world. Which is why most programs for Linux are available to download in both binary as well as source code formats (with the source code typically available on a git repository like github, or as a single compressed archive (.tar.gz)).
But when a particular program isn’t available in a binary format, you’ll need to compile it from the source code. Doing this is a pretty common practice for projects that are still in-development - say you want to run the latest Mesa graphics driver, which may contain bug fixes or some performance improvements that you’re interested in - you would then download the source code and compile it yourself.
Another scenario is maybe you might want a program to be optimised specifically for your CPU for the best performance - in which case, you would compile the code yourself, instead of using a generic binary provided by the programmer. And some Linux distributions, such as CachyOS, provide multiple versions of such pre-optimized binaries, so that you don’t need to compile it yourself. So if you’re interested in performance, look into the topic of CPU microarchitectures and CFLAGS.
Sources for examples above: http://timelessname.com/elfbin/
deleted by creator