

- cross-posted to:
- [email protected]
- cross-posted to:
- [email protected]
You must log in or register to comment.
“LLMs such as they are, will become a commodity; price wars will keep revenue low. Given the cost of chips, profits will be elusive,” Marcus predicts. “When everyone realizes this, the financial bubble may burst quickly.”
Please let this happen
Market crash and third world war. What a time to be alive!
Over-promising and under-delivering are normal - that goes for both directions. I think it’s undeniable that machine learning / AI has been improving at a steady pace. Sure, the current cycle will reach its peak, but there will be another and another. I don’t believe AGI is a matter of if, more a matter of when. Whatever technology they’re using now is not it, but it may play a part and even if it doesn’t become AGI, it will be one more thing to tick off and explore new roads.
As someone said “this is the worst AI will ever be”. It’ll keep getting better. We just have to be prepared for the next cycle and not be caught off-guard. But knowing humans, we are terrible at long-term planning and preparing. The next cycle will catch the majority with their pants down and we will be scrambling to pull them up while whatever it is was developed changes our world yet again.
I wish just once we could have some kind of tech innovation without a bunch of douchebag techbros thinking it’s going to solve all the world’s problems with no side effects while they get super rich off it.
… bunch of douchebag techbros thinking it’s going to solve all the world’s problems with no side effects…
one doesn’t imagine any of them even remotely thinks a technological panacaea is feasible.
… while they get super rich off it.
because they’re only focusing on this.
Oh they definitely exist. At a high level the bullshit is driven by malicious greed, but there are also people who are naive and ignorant and hopeful enough to hear that drivel and truly believe in it.
Like when Microsoft shoves GPT4 into notepad.exe. Obviously a terrible terrible product from a UX/CX perspective. But also, extremely expensive for Microsoft right? They don’t gain anything by stuffing their products with useless annoying features that eat expensive cloud compute like a kid eats candy. That only happens because their management people truly believe, honest to god, that this is a sound business strategy, which would only be the case if they are completely misunderstanding what GPT4 is and could be and actually think that future improvements would be so great that there is a path to mass monetization somehow.
That’s not what’s happening here. Microsoft management are well aware that AI isn’t making them any money, but the company made a multi billion dollar bet on the idea that it would, and now they have to convince shareholders that they didn’t epicly fuck up. Shoving AI into stuff like notepad is basically about artificially inflating “consumer uptake” numbers that they can then show to credulous investors to suggest that any day now this whole thing is going to explode into an absolute tidal wave of growth, so you’d better buy more stock right now, better not miss out.
No no, I disagree I think that shoving AI into all these apps is a solid plan on their behalf. People are going to stop recall and shut it off. So instead they put AI components into every app, It now has the right to overview everything you’re doing and every app collects data on you sending it home to update their personalized models for you so they can better sell you products.
Yeah my management was all gungho about exploiting AI to do all sorts of stuff.
Like read. Not generative AI crap, but read. They came to us and said quite literally: “how can we use something like ChatGPT and make it read.”
I don’t know who or how they convinced them to use something that wasn’t generative AI, but it did convince me that managers think someone being convincing and confident is correct all the time.
Being convincing and confident without actually knowing is how 9/10s of them make it to the C suite.
That’s probably why they don’t worry about confidently incorrect AI.
Salesmanship is the essence of management at those levels.
Which brings us back around to the original subject of this thread - tech bros - in my own experienced in Tech recently and back in the 90s boom, this generation of founders and “influencers” aren’t techies, they’re people from areas heavy on salesmanship, not actually on creating complex things that objectivelly work.
The complete total dominance of sales types in both domains id why LLMs are being pushed the way they are as if they’re some kind of emerging-AGI and lots of corporates believe it and are trying to hammer those square pegs into round holes even though the most basic of technical analises would tell them that it doesn’t work like that.
Ultimately since the current societal structures we have massively benefit that kind or personality, we’re going to keep on having these kinds of barely-useful-stuff-insanely-hyped-up cycles wasting tons of resources because salesmanship is hardly a synonym for efficiency or wisdom.
Some are just opportunists, but there are certainly true believers — either in specific technologies, or pedal-to-the-metal growth as the only rational solution to the world’s problems.
Andreessen is pretty open about it: https://a16z.com/the-techno-optimist-manifesto/
I think Andreessen is lying and the “techno optimist manifesto” is a ruse for PR.
a16z has been involved in various crypto pump and dumps. They are smart enough to know that something like “play to earn” is not sustainable and always devolves into a pyramid scheme. Doesn’t stop them from getting in early and dumping worthless tokens on the marks.
The manifesto honestly reads like it was written by a teenager. The style, the tone, the excessive quotes from economists. This is pretty typical stuff for American oligarch polemics, no?
True, they just sell it to their investors as a panacea
Soooo… Without capitalism?
Pretty much.
Of course most don’t actually even believe it, that’s just the pitch to get that VC juice. It’s basically fraud all the way down.
AI was 99% a fad. Besides OpenAI and Nvidia, none of the other corporations bullshitting about AI have made anything remotely useful using it.
Absolutely not true. Disclaimer, I do work for NVIDIA as a forward deployed AI Engineer/Solutions Architect—meaning I don’t build AI software internally for NVIDIA but I embed with their customers’ engineering teams to help them build their AI software and deploy and run their models on NVIDIA hardware and software.
To state this as simply as possible: I wouldn’t have a job if our customers weren’t seeing tremendous benefit from AI technology. The companies I work with typically are very sensitive to CapX and OpX costs of AI—they self-serve in private clouds. If it doesn’t help them make money (revenue growth) or save money (efficiency), then it’s gone—and so am I. I’ve seen it happen; entire engineering teams laid off because a technology just couldn’t be implemented in a cost-effective way.
LLMs are a small subset of AI and Accelerated-Compute workflows in general.
To state this as simply as possible: I wouldn’t have a job if our customers weren’t seeing tremendous benefit from AI technology.
Right because corporate management doesn’t ever blindly and stupidly overinvest in fads that blow up in their faces…
I work with typically are very sensitive to CapX and OpX costs of AI—they self-serve in private clouds. If it doesn’t help them make money (revenue growth) or save money (efficiency), then it’s gone—and so am I.
You clearly have no clue what you’re on about. As someone with a degrees and experience in both CS and Finance all I have to say is that’s not at all how these things work. Plenty of companies lose money on these things in the hopes that their FP&A projection fever dreams will come true. And they’re wrong much more often than you seem to think. FP&A is more art than science and you can get financial models to support any argument you want to make to convince management to keep investing in what you think they should. And plenty of CEOs and boards are stupid enough to buy it. A lot of the AI hype has been bought and sold that way in the hopes that it would be worthwhile eventually or that other alternatives can’t be just as good or better.
I’ve seen it happen; entire engineering teams laid off because a technology just couldn’t be implemented in a cost-effective way.
This is usually what happens once they finally realize spending money on hype doesn’t pay off and go back to more established business analytics, operations research, and conventional software which never makes mistakes if it’s programmed correctly.
LLMs are a small subset of AI and Accelerated-Compute workflows in general.
No one ever said otherwise. And we’re talking about AI only, no moving the goalposts to accelerated computing, which is a mechanism through which to implement a wide range of solutions and not a specific one in and of itself.
That’s fair. I see what I see at an engineering and architecture level. You see what you see at the business level.
That said. I stand by my statement because I and most of my colleagues in similar roles get continued, repeated and expanded-scope engagements. Definitely in LLMs and genAI in general especially over the last 3-5 years or so, but definitely not just in LLMs.
“AI” is an incredibly wide and deep field; much more so than the common perception of what it is and does.
Perhaps I’m just not as jaded in my tech career.
operations research, and conventional software which never makes mistakes if it’s programmed correctly.
Now this is where I push back. I spent the first decade of my tech career doing ops research/industrial engineering (in parallel with process engineering). You’d shit a brick if you knew how much “fudge-factoring” and “completely disconnected from reality—aka we have no fucking clue” assumptions go into the “conventional” models that inform supply-chain analytics, business process engineering, etc. To state that they “never make mistakes” is laughable.
That’s fair. I see what I see at an engineering and architecture level. You see what you see at the business level.
I respect that. Finance was my old career and I hated it. I liked coding more so I went back got my M.S. in CS and now do embedded software which I love. I left finance specifically because of what both of us have talked about. It’s all about using nunber to tell whatever story you want and it’s filled with corporate politics. I hated that world. It was disgusting and people were terrible two faced assholes.
That said. I stand by my statement because I and most of my colleagues in similar roles get continued, repeated and expanded-scope engagements. Definitely in LLMs and genAI in general especially over the last 3-5 years or so, but definitely not just in LLMs.
“AI” is an incredibly wide and deep field; much more so than the common perception of what it is and does.
So I think I need to amend what I said before. AI as a whole is definitely useful for various things but what makes it a fad is that companies are basically committing the hammer fallacy with it. They’re throwing it at everything even things where it may not be a good solution just to say hey look we used AI. What I respect about you guys at Nvidia is that you all make really awesome AI based tools and software that actually does solve problem that other types of software and tools either cannot do or cannot do well and that’s how it should be.
At the same time I’m also a gamer and I really hope Uncle Jensen doesn’t forget about us and how we literally were his core market for most of Nvidia’s history as a business.
Now this is where I push back. I spent the first decade of my tech career doing ops research/industrial engineering (in parallel with process engineering). You’d shit a brick if you knew how much “fudge-factoring” and “completely disconnected from reality—aka we have no fucking clue” assumptions go into the “conventional” models that inform supply-chain analytics, business process engineering, etc. To state that they “never make mistakes” is laughable.
What I said was that traditional software if programmed correctly doesn’t make mistakes. As for operations research and supply chain optimization and all the rest of it, it’s not different that what I said about finance. You can make the models tell any story you want and it’s not even hard but the flip side is that the decision makers in your organization should be grilling you as an analyst on how you came up with your assumptions and why they make sense. I actually think this is an area where AI could be useful because if trained right it has no biases unlike human analysts.
The other thing to sort of take away from what I said is the “if it is programmed correctly” part which is also a big if. Humans make mistakes and we see it a lot in embedded where in some cases we need to flash our code onto a product and deploy it in a place where we won’t be able to update it for a long time or maybe ever and so testing and making sure the code works right and is safe is a huge thing. Tool like Rust help to an extent but even then errors can leak through and I’ve actually wondered how useful AI based tools could eventually be in proving the correctness of traditional software code or finding potential bugs and sources of unsafety. I think a deep learning based tool could make formal verification of software a much cheaper and more commonplace practice and I think on the hardware side they already have that sort of thing. I know AMD/Xilinx use machine learning in their FPGA tools to synthesize designs so I don’t see why we couldn’t use such a thing for software that needs to be correct the first time as well.
So that’s really it. My only gripe at all with AI and DL in particular is when executive who have no CS or engineering background throw around the term AI like it’s the magic solution to everything or always the best option when the reality is that sometimes it is and other times it isn’t and they need to have a competent technology professional make that call.
lalal AI has made some great innovations in taking songs and separating them into vocals and instrumentals. that’s a game changer for remix artists.
other than that niche utility and a handful of others, AI is largely bullshit.
Nvidia made money, but I’ve not seen OpenAI do anything useful, and they are not even profitable.
ChatGPT is basically the best LLM of its kind. As for Nvidia I’m not talking about hardware I’m talking about all of the models it’s trained to do everything from DLSS and ACE to creating virtual characters that can converse and respond naturally to a human being.
I would say LLMs specifically are in that ball park. Things like machine vision have been boringly productive and relatively un hyped.
There’s certainly some utility to LLMs, but it’s hard to see through all the crazy over estimations and being shoved everywhere by grifters.
Thank fuck. Can we have cheaper graphics cards again please?
I’m sure a RTX 4090 is very impressive, but it’s not £1800 impressive.
nope, if normal gamers are already willing to pay that price, no reason for nvidia to reduce them.
There’s more 4090 on steam than any AMD dedicated GPU, there’s no competition
I swapped to AMD this generation and it’s still expensive.
A well researched pre-owned is the way to go. I bought a 6900xt a couple years ago for a deal.
I used to buy broken video cards on ebay for ~$25-50. The ones that run, but shut off have clogged heat sinks. No tools or parts required. Just blow out the dust. Obviously more risky, but sometimes you can hit gold.
If you can buy a ten and one works, you’ve saved money. Two work and you’re making money. The only question is whether the tenth card really will work or not.
And are you really interested in selling the extras?
For the price of the bundle? Sure.
Graphics cards are so bulky nowadays it’s often hard to even fit two on one mobo, as much as I’d love to see 10 GPUs all linked up.
I used to get EVGA bstock which was reasonable but they got out of the business 😞
Sorry, crypto is back in season.
Just wait for the 5090 prices…
I just don’t get whey they’re so desperate to cripple the low end cards.
Like I’m sure the low RAM and speed is fine at 1080p, but my brother in Christ it is 2024. 4K displays have been standard for a decade. I’m not sure when PC gamers went from “behold thine might from thou potato boxes” to “I guess I’ll play at 1080p with upscaling if I can have a nice reflection”.
4k displays are not at all standard and certainly not for a decade. 1440p is. And it hasn’t been that long since the market share of 1440p overtook that of 1080p according to the Steam Hardware survey IIRC.
Maybe not monitors, but certainly they are standard for TVs (which are now just monitors with Android TV and a tuner built in).
Well, people aren’t sticking 4090s in their Samsung smart TVs, so idk that matters.
That doesn’t really matter if people on PC don’t game on it, does it?
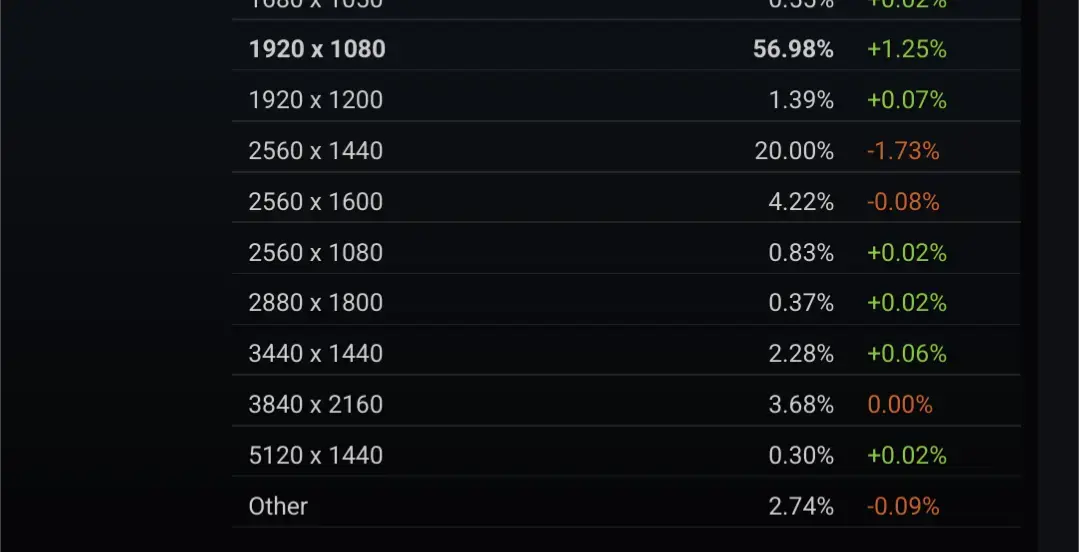
These are the primary display resolutions from the Steam Hardware Survey.
You’re so close to the answer. Now, why are PC gamers the ones still on 1080 and 1440 when everyone else has moved on?
I think it’s just an upselling strategy, although I agree I don’t think it makes much sense. Budget gamers really should look to AMD these days, but unfortunately Nvidia’s brand power is ridiculous.
An the issue for PC gamers is that Nvidia has spent the last few years convincing devs to shovel DLSS into everything, rather than a generic upscaling solution that other vendors could just drop their own algorithms into, meaning there’s a ton of games that won’t upscale nicely on anything else.
Of course it’ll crash. Saying it’s imminent though suggests someone needs to exercise their shorts.
deleted by creator
Because nobody could have possibly saw that coming. /s
I think I’ve heard about enough of experts predicting the future lately.
Great!! …I don’t what chatGPT to go anywhere, I use it every day and Google has become assss.
Sigh I hope LLMs get dropped from the AI bandwagon because I do think they have some really cool use cases and love just running my little local models. Cut government spending like a madman, write the next great American novel, or eliminate actual jobs are not those use cases.
Huh?
The smartphone improvements hit a rubber wall a few years ago (disregarding folding screens, that compose a small market share, improvement rate slowed down drastically), and the industry is doing fine. It’s not growing like it use to, but that just means people are keeping their smartphones for longer periods of time, not that people stopped using them.
Even if AI were to completely freeze right now, people will continue using it.
Why are people reacting like AI is going to get dropped?
People differentiate AI (the technology) from AI (the product being peddled by big corporations) without making clear that nuance (Or they mean just LLMs, or they aren’t even aware the technology has a grassroots adoption outside of those big corporations). It will take time, and the bubble bursting might very well be a good thing for the technology into the future. If something is only know for it’s capitalistic exploits it’ll continue to be seen unfavorably even when it’s proven it’s value to those who care to look at it with an open mind. I read it mostly as those people rejoicing over those big corporations getting shafted for their greedy practices.
the bubble bursting might very well be a good thing for the technology into the future
I absolutely agree. It worked wonders for the Internet (dotcom boom in the 90s), and I imagine we’ll see the same w/ AI sometime in the next 10 years or so. I do believe we’re seeing a bubble here, and we’re also seeing a significant shift in how we interact w/ technology, but it’s neither as massive or as useless as proponents and opponents claim.
I’m excited for the future, but not as excited for the transition period.
deleted by creator
I initially started with natural language processing (small language models?) in school, which is a much simpler form of text generation that operates on words instead of whatever they call the symbols in modern LLMs. So when modern LLMs came out, I basically registered that as, “oh, better version of NLP,” with all its associated limitations and issues, and that seems to be what it is.
So yeah, I think it’s pretty neat, and I can certainly see some interesting use-cases, but it’s really not how I want to interface with computers. I like searching with keywords and I prefer the process of creation more than the product of creation, so image and text generation aren’t particularly interesting to me. I’ll certainly use them if I need to, but as a software engineer, I just find LLMs in all forms (so far) annoying to use. I don’t even like full text search in many cases and prefer regex searches, so I guess I’m old-school like that.
I’ll eventually give in and adopt it into my workflow and I’ll probably do so before the average person does, but what I see and what the media hypes it up to be really don’t match up. I’m planning to set up a llama model if only because I have the spare hardware for it and it’s an interesting novelty.
People are dumping billions of dollars into it, mostly power, but it cannot turn profit.
So the companies who, for example, revived a nuclear power facility in order to feed their machine with ever diminishing returns of quality output are going to shut everything down at massive losses and countless hours of human work and lifespan thrown down the drain.
This will have an economic impact quite large as many newly created jobs go up in smoke and businesses who structured around the assumption of continued availability of high end AI need to reorganize or go out of business.
Search up the Dot Com Bubble.
Because in some eyes, infinite rapid growth is the only measure of success.
Hope?
Because novelty is all it has. As soon as it stops improving in a way that makes people say “oh that’s neat”, it has to stand on the practical merits of its capabilities, which is, well, not much.
I’m so baffled by this take. “Create a terraform module that implements two S3 buckets with cross-region bidirectional replication. Include standard module files like linting rules and enable precommit.” Could I write that? Yes. But does this provide an outstanding stub to start from? Also yes.
And beyond programming, it is otherwise having positive impact on science and medicine too. I mean, anybody who doesn’t see any merit has their head in the sand. That of course must be balanced with not falling for the hype, but the merits are very real.
There’s a pretty big difference between chatGPT and the science/medicine AIs.
And keep in mind that for LLMs and other chatbots, it’s not that they aren’t useful at all but that they aren’t useful enough to justify their costs. Microsoft is struggling to get significant uptake for Copilot addons in Microsoft 365, and this is when AI companies are still in their “sell below cost and light VC money on fire to survive long enough to gain market share” phase. What happens when the VC money dries up and AI companies have to double their prices (or more) in order to make enough revenue to cover their costs?
Nothing to argue with there. I agree. Many companies will go out of business. Fortunately we’ll still have the llama3’s and mistral’s laying around that I can run locally. On the other hand cost justification is a difficult equation with many variables, so maybe it is or will be in some cases worth the cost. I’m just saying there is some merit.
The merits are real. I do understand the deep mistrust people have for tech companies, but there’s far too much throwing out of the baby with the bath water.
As a solo developer, LLMs are a game-changer. They’ve allowed me to make amazing progress on some of my own projects that I’ve been stuck on for ages.
But it’s not just technical subjects that benefit from LLMs. ChatGPT has been a great travel guide for me. I uploaded a pic of some architecture in Berlin and it went into the history of it, I asked it about some damage to an old church in Spain - turned out to be from the Spanish civil war, where revolutionaries had been mowed down by Franco’s firing squads.
Just today, I was getting help from an LLM for an email to a Portuguese removals company. I sent my message in English with a Portuguese translation, but the guy just replied back with a single sentence in broken English:
“Yes a can , need tho mow m3 you need delivery after e gif the price”
The first bit is pretty obviously “Yes I can” but I couldn’t really be sure what he was trying to say with the rest of it. So I asked ChatGPT who responded:
It seems he’s saying he can handle the delivery but needs to know the total volume (in cubic meters) of your items before he can provide a price. Here’s how I’d interpret it:
“Yes, I can [do the delivery]. I need to know the [volume] in m³ for delivery, and then I’ll give you the price.”
Thanks to LLMs, I’m able to accomplish so many things that would have previously taken multiple internet searches and way more effort.
Okay now justify the cost it took to create the tool.
People pay real money for smartphones.
People pay real Money for AIaaS as well…
It’s absurdly unprofitable. OpenAI has billions of dollars in debt. It absolutely burns through energy and requires a lot of expensive hardware. People aren’t willing to pay enough to make it break even, let alone profit
Eh, if the investment dollars start drying up, they’ll likely start optimizing what they have to get more value for fewer resources. There is value in AI, I just don’t think it’s as high as they claim.
Oh nice, another Gary Marcus “AI hitting a wall post.”
Like his “Deep Learning Is Hitting a Wall” post on March 10th, 2022.
Indeed, not much has changed in the world of deep learning between spring 2022 and now.
No new model releases.
No leaps beyond what was expected.
\s
Gary Marcus is like a reverse Cassandra.
Consistently wrong, and yet regularly listened to, amplified, and believed.
🤷♂️ I only use local generators at this point,so I don’t care.












